-
ClickHouse MergeTree Read 执行流程
Overview
这里要分析的主要是生成 pipeline 以后,执行 pull 操作时,ISource::work() 的实际执行流程。本文基于 v21.10 版本代码进行分析。
ISource work 方法执行流程
先看一个大致的执行流程描述。

ISource::work 方法主要是执行的是实际 Processor 的 generate() 方法。我们这里主要分析 readFromPool 这条执行链路,最终生成的是 MergeTreeBaseSelectProcessor, work 会调用到 MergeTreeBaseSelectProcessor::generate() 方法。generate() 方法执行结束后,会以 Chunk 的形式返回这次读取的数据,ISource 会将这个 Chunk 设置为 currentChunk,在下一次执行 prepare 方法时,通过 OutputPort,将 currentChunk 推送给已连接的其他 Processor 的 InputPort。
MergeTreeBaseSelectProcessor 的 generate() 方法首先会去获取一个 read task。这个 task 是一个有状态的结构,如果当前的 task 是一个未完成的状态,则直接拿到这个 task。否则,会通过调用 getNewTask 方法,从 MergeTreeReadPool 中再获取一个新的 task。
每个 task 会包含一个 MarkRanges 结构,包含了它负责读取的所有 mark range。每个 mark range 对应连续的多个 mark。
在获取到 task 之后,MergeTreeBaseSelectProcessor 会进行 range reader 的初始化,之后调用 readFromPartImpl 继续处理。在读取之前,会首先进行 rows_to_read 的计算,通过 max bytes 和 max rows 两个维度的限制,计算出这次读操作最大能读取的行数。最终,调用 MergeTreeRangeReader 的 read 方法,读取指定行数并返回。
上述的流程会不断重复,直到获取到 query 所有的结果。这里涉及到一个关键问题是,如何从上一次的位置继续进行读取操作?
首先,MergeTreeBaseSelectProcessor 会维护一个当前未完成的 task 结构,这个 task 包含了需要读取的所有 MarkRange 信息,这些信息以一个队列的方式进行管理,随着读取的进行,待处理的 MarkRange 不断弹出队列,直至队列为空。MarkRange 从队列中取出以及实际的读取操作由 MergeTreeRangeReader 负责。MergeTreeRangeReader 会为每个当前进行读取的 MarkRange 创建一个 Stream 对象进行读取。一次读取操作可能在读取到某个 MarkRange 的某个位置时结束。读取结束时,MergeTreeRangeReader 会记录好当前读取的 offset,在下一次读取时,再从这里开始进行。当一个 MarkRange 读取完成后,MergeTreeRangeReader 会读取 task 的下一个 MarkRange,继续后续的读取操作。下面对 MergeTreeRangeReader 的读取流程进行详细分析。
MergeTreeRangeReader 读取流程
这里介绍的是一个普通的读取操作的 MergeTreeRangeReader 层操作流程,不考虑 prewhere 的情况。
MergeTreeBaseSelectProcessor 的 readFromPartImpl 通过 read task 的 range_reader 的 read 方法进行实际的读取操作。range_reader 是一个 MergeTreeRangeReader 类型对象,其 read 方法需要给定两个参数:rows_to_read,指定这次读取操作需要读取的最大行数,这个值是通过 current_max_block_size_rows 以及 current_preferred_block_size_bytes 预估出来的,通常最小是 index_granularity 的行数,最大为 65536; 另一个参数是 read task 的 mark_ranges,如上所述,这个是一个包含 task 负责的所有 mark range 的队列,MergeTreeRangeReader 会实际负责从这个队列里不断取出 mark range,进行读写,直至队列为空。
MergeTreeRangeReader 的 read 也采用了分层的设计,MergeTreeRangeReader 类主要负责整个 read task 的操作流程管理。对于每个 mark_range, MergeTreeRangeReader 通过一个 Stream 类来对读取的流程进行管理。而对于每个 mark 的读取,则通过 DelayedStream 类来进行实际操作。

在读取时,MergeTreeRangeReader 首先会检查一个 Stream 是否结束,如果结束了,会调用 finalize 方法,进行最后一部分待读取部分的处理。这里需要注意的是,判断一个 Stream 是否结束的方法是判断当前 mark 是否是最后一个,而不是已经没有数据可读,因此,Stream 结束并不代表 read 操作已经结束,仍需要调用 finalize 来进行后续的处理。当 finalize 调用结束以后,如果 mark_ranges 队列不为空,则弹出一个新的 mark_range, MergeTreeRangeReader 为其创建一个新的 Stream 对象,进行接下来的读取操作。
Stream 未结束之前,都是调用 Stream::read 方法来进行正常的读取操作,该方法最终会调用到实际的 MergeTreeReader(默认是 MergeTreeReaderWide) 来处理真正的读取操作。每次的调用会返回 rows_read, 并记录 current_mark, offset_after_current_mark 等状态信息,实际读取的信息通过一个 Columns 结构的引用传递回去。整体的 read 流程如下图所示。

-
ClickHouse QueryPipeline 相关代码分析
Overview
QueryPipeline 是 CK 中一条 select query 最终的物理执行计划。本文尝试分析 QueryPipeline 的创建过程,一些相关结构之间的关联,以及各个结构所起到的作用。
本文基于 22.3.7.28-lts 版本分析。
QueryPipeline 创建
首先在 InterpreterSelectQuery 的 execute() 中,调用 query_plan.buildQueryPipeline 来生成 QueryPipelineBuilder。再通过 QueryPipelineBuilder::getPipeline(QueryPipelineBuilder) 来创建真正的 pipeline。
query_plan.buildQueryPipeline 首先会执行 query plan 的 optimize,之后从 source step 开始,调用每个 QueryPlanStep 的 updatePipeline,以上一个 step 生成 pipelines 作为参数,生成当前 step 的 QueryPipelineBuilder,并将其设置为 last_pipeline。等所有的 step 执行完 updatePipeline 之后,返回最后的 last_pipeline,也就是最终的 QueryPipelineBuilder。
QueryPipelineBuilder::getPipeline 中,会基于参数得 QueryPipelineBuilder 的 pipe 创建来QueryPipeline。QueryPipeline 构造时,如果发现传入得 pipe 的 numOutputPorts 大于 0, 则添加一个 ResizeProcessor,将所有的 outputs 都接到这个 ResizeProcessor 上,确保到这里多个线程的执行结果都汇总到一起。
需要注意的是,interpreter 返回结果中的 pipeline,不是最终的 pipeline,还需要以下的两步:
- 在 executeQuery.cpp 的 executeQueryImpl 中,对于 pulling 的 pipeline,会在最后添加一个 LimitsCheckingTransform processor,用于进行 time limit 和 size limit 的判断,以及执行信息的统计(result_rows, result_bytes, execution_time)
- 在 PullingAsyncPipelineExecutor 的构建时,会加上 LazyOutputFormat processor
至此 pipeline 才算构建完成。
Pipe 创建
QueryPipelineBuilder 中会包含一个 pipe 结构,这个结构主要用于进行 processors 之间的连接,是 plan 到 pipeline 转换过程中的关键结构。这里分析 pipe 的创建以及关键的连接操作。
创建 pipe 时,首先通过所有的 main Sources processors 创建。
pipe 在添加 sources 时,是每个 source 创建一个 Pipe,然后再调用 unitePipes 将所有的 Pipes 连接成一个。
Pipe construction
1 将 source 的 outputs 的 front 添加到 output_ports 中
2 将 header 设置为 output_ports.front() 的 header
3 将 source processor 添加到 processors 中
4 设置 max_parallel_streams 为 1
unitePipes
1 创建一个新的 Pipe res
2 res 的 holder 设置为最后一个 pipe 的 holder
3 res 的 header 设置为 pipes 的 common header
4 将所有 pipes 的 processors 添加到 res 的 processors 中
5 将所有 pipes 的 output_ports 添加到 res 的 output_ports 中
6 累加所有 pipes 的 max_parallel_streams,赋值给 res 的 max_parallel_streams
对于 transform processor 的添加,pipe 提供两种接口,其中 addSimpleTransform 接收一个 getter 的 transform processor 创建方法,为每个 output 创建一个对应的 transform processor,并进行连接;addTransform 直接接受一个 transform processor,将所有的 outputs 都和这一个 transform processor 进行连接。
addSimpleTransform(const ProcessorGetter & getter)
将 transform processor 添加给所有的 output_ports。
具体来说,对每个 output_port:
1 基于传入的 getter 函数,创建 transform processor
- 基于传入的 input header 和 output header 创建 input port 和 output port
2 将当前 output port 和 transform 的 input port 做 connect
3 将这个 output port 设置为 transform 的 output port
4 processors 中添加 transform
addTransform(ProcessorPtr transform, OutputPort * totals, OutputPort * extremes)
将传进来的 transform processor inputs 和所有的 output ports 连接
1 获取 transform 所有的 input ports
2 将每个 input port 和 output ports 顺序连接
3 将 outputs 设置为 transform 的 outputs
4 将 outputs 中的每个 元素,都添加到 pipe 的 output_ports 中
5 将 header 设置为 output_ports 第一个的 header
6 将 transform processor 添加到 processors 中
7 设置 max_parallel_streams 为当前 max_parallel_streams 与 output_parts.size() 的最大值
其他几个问题
processors 如何进行连接
- 每个 processor 在创建时,会根据 input header 和 output header 来创建 input 以及 output ports。每次 pipe 添加 processor 时,会将当前的 output ports 和 processor 的 input port 连接,具体操作为:
- 分别设置为对方的 output_port 以及 input_port
- 分别设置 out_name 与 in_name 为 output 和 input processor 的 name
- 初始化 input.state, output.state 设置为 input.state
如果多个 processors 的 output 是同一个 processor, ExecutingGraph 如何调度
- 对于 inputs 来说,每个 processor 都会将 output processor 添加到 edges 中,然后调用一次 output processor 的 prepare 方法。这种汇聚 inputs 的 processor 一般是一个 ResizeProcessor,在 prepare 的时候,只负责将 input 的数据 push 到 output processor 去,然后继续返回 needData 的状态。
多个 sources 是在什么时候合并的?是否有固定的合并操作?
- QueryPipeline 构造时,引入 ResizeProcessor,进行多线程 inputs 的合并,之后就都是单线程操作
ISource 的 outputs 如何初始化?
ISource 的 construction:
ISource::ISource(Block header) : IProcessor({}, {std::move(header)}), output(outputs.front()) { }用的是 IProcessor 创建时候的 outputs 的第一个,而 IProcessor 的 outputs 是基于 header 创建的, 这里主要是创建了一个带 header 的 OutputPort。header 来自于
MergeTreeBaseSelectProcessor::transformHeader 操作,该操作会基于 required columns 等信息算出来的需要实际读取的 columns,也就是 OutputPort 的 header 记录的是 ISource 要读取的列名称。
-
ClickHouse ExecutingGraph 相关代码分析
Overview
每条 select query 在生成完 Processors 之后,准备执行时,都会创建一个 PullingAsyncPipelineExecutor 结构来负责整体 pipeline 的 pull 式执行,其中 pipeline 的执行是被封装在一个 PipelineExecutor 结构中管理,而 PipelineExecutor 为每个 Pipeline 的 Processors 维护了两个主要的数据结构来管理整体的执行,一个是负责管理各个 Processors 之间的调用关系和状态的 ExecutingGraph,另一个是负责具体执行的 ExecutorTasks。本文主要介绍 ExecutingGraph 的基本结构与主要方法设计。
基本结构
Node:每个 processor 建立一个,负责维护 Processor 的执行状态
- updated_output_ports
- updated_input_ports
Edge:
- to:连接 node 的 id
- input_port_number:这个 output port 对应的 input port 在 to Processor 的 inputs 中的 port number
- output_port_number:output port 在 from Processor 的 outputs 中的 port number
- update_info: Port 会操作的信息,edge 会将 update_info 的 id 设置为自己,会将 update_info 的 update_list 设置为 node 的 post_updated_input_ports (back edges) 或者是 post_updated_output_ports (direct edges)
processors_map:IProcessor 到 node 的 id 的 map
Construction
基于给定的 processors,包含创建 nodes 和创建 edges 两个步骤。
创建 nodes
针对给定的每个 processor,都创建一个 node,将 processor 和 node id 的对应关系保存到 processors_map 中。
创建 edges
对每个 node,调用 addEdges 方法,为每个 node 创建 edges
addEdges
对一个 node 来说,首先添加其对应 processor 的 inputs,再添加其 outputs
添加 inputs / outputs
- 对该 node 对应的每个 input port / output port,获取其对应的 output port / input port的 processor 作为 to processor
- 得到 output port / input port 在 processor 中的 output port number / input port number
- 创建 edge:
Edge edge(0, true, from_input, output_port_number, &nodes[node]->post_updated_input_ports); / Edge edge(0, false, input_port_number, from_output, &nodes[node]->post_updated_output_ports); - 调用 addEdge:
- 首先查找 to processor 是否已经在 processors_map 中了,如果不在,就会 throw exception
- 将 edge→to 设置为 to processor 对应的 node
- 将 edge 添加到 nodes[node]→back_edges / nodes[node]→direct_edges 结构中
- 将 edge 的 update_info.id 设置为 edge 自己
- from_input 对应的 input port 设置 update info 为 edge 的 update_info
initializeExecution
选出所有的没有 outputs 的 processor,也就是所有的 IOutputFormat processors 添加到 stack 中,将 node 的 status 设置为
ExecutingGraph::ExecStatus::Preparing对于每个 stack 中的 processor,调用 updateNode
updateNode
参数为 processor_id, queue, 以及 async_queue。processor_id 表示要更新哪个 node;queue 是一个同步执行的 task queue,updateNode 方法会将 ready 的 node 添加到这个 queue 中,之后由 ExecutorTasks 进行处理;async_queue 和 queue 的使用场景类似,只是只会处理 status 为 async 的 processors。
updateNode 方法在 initializeExecution 以及每个 processor 的 work 执行后会被调用,主要负责 processors 的调用前准备工作,以及 processor node 执行的调度。
对于 IOutputFormat Processor,第一次调用 prepare,会进行以下操作
/// 会将其 inputs 添加到 post_updated_input_ports 中 input.setNeeded(); if (!input.hasData()) return Status::NeedData;对 node post_updated_input_ports 中的每个 edge,添加到 updated_edges 中,之后调用 edge→update_info.trigger() 来将 update_info 的 version+1
继续进入下一层循环,这时 updated_processors 为 empty
- 获取 updated_edges 最上面的 edge
- 得到 edge→to 指向的 node,这里应该是一条 back_edge, 所以指向的是之前 node 的一个 input
- 将 edge 的 output_port_number 添加到 node.updated_output_ports 中
- 如果 node 的 status 为 idle:
- 将 status 设置为 ExecutingGraph::ExecStatus::Preparing
- 将 edge→to 添加到 updated_processors 中
继续进行时,又进入到 update_processors 不为空的逻辑中。
如此循环,直到 updated_edges 和 updated_processors 都为空位置。
由此可见,第一次调用 processors 的 prepare 是从后往前调用的。
全部执行完之后,queue 中应该只包含 source processors, 并且这些 node 的 status 都会被设置为
ExecutingGraph::ExecStatus::Executing,其他 processors 会被设置为 ExecutingGraph::ExecStatus::Idle
updateNode 在每个 processor 执行完 work 以后,还会被调用一次,只不过这次应该是从前往后调用。
-
ClickHouse Merge 执行流程分析(概述与后台任务调度逻辑)
基本流程
Clickhouse 的 merge 的大致的流程为:后台线程周期性运行一个调度程序,判断是否有需要被 merge 的 data parts。如果有,则生成一个 merge task 交给后台的一个调度池等待执行。 当等待 tasks 数量小于一定值时,merge task 会被触发执行。执行时,会创建一个临时 data part 写入被 merge 的数据,执行完成后,临时 data part 按照最终 part 的 info 信息重命名,得到最终的 data part,至此一次 merge 执行结束。
以上可以看到 merge 操作主要分为几个部分:
- 后台异步周期性任务调度
- 待 merge 的 data parts 的筛选
- 实际 merge task 的执行
现在按照这三个部分来进行详细分析,本文先分析异步任务调度的逻辑.
异步任务调度
这里需要解答以下几个问题:
- 异步任务调度有几个层次?
- 每个层次的相关模块是在何时启动的?
- 如何实现周期性的调度?
这里基于 21.11.5 版本的代码来进行分析。这个版本中包含一个 BackgroundJobsAssignee 类,主要负责异步任务的生成与提交,连接 storageMergeTree 层与实际的异步任务执行层。该类定义如下:
class BackgroundJobsAssignee : public WithContext { private: MergeTreeData & data; /// Settings for execution control of background scheduling task BackgroundTaskSchedulingSettings sleep_settings; /// Useful for random backoff timeouts generation pcg64 rng; /// How many times execution of background job failed or we have /// no new jobs. std::atomic<size_t> no_work_done_count{0}; /// Scheduling task which assign jobs in background pool BackgroundSchedulePool::TaskHolder holder; /// Mutex for thread safety std::mutex holder_mutex; }data 是与其对应的 MergeTreeData 对象的引用,用来访问 MergeTreeData 相关的任务生成函数。这个 MergeTreeData 是 StorageMergeTree 的基类。在 MergeTreeData 对象也会包含这个 BackgroundJobsAssignee 对象,定义如下:
class MergeTreeData : public IStorage, public WithMutableContext { ... protected: ... BackgroundJobsAssignee background_operations_assignee; BackgroundJobsAssignee background_moves_assignee; ... }background_operations_assignee 是主要的异步任务调度代理,background_moves_assignee 则主要负责 part move 相关的任务的执行。
每个 BackgroundJobsAssignee 在启动后,不是立即执行其后台的调度逻辑的。每次调度都需要提交到一个全局的 BackgroundSchedulePool 中进行调度,如果当前同时要运行后台调度任务的 StorageMergeTree 数量小于一个阈值,才会执行其调度逻辑,否则,会延后执行。这部分的逻辑包含在了 BackgroundSchedulePool::TaskHolder 这个类中,每个 BackgroundJobsAssignee 会包含一个 holder 的对象。
异步任务的实际执行的 executor 包含在 Context 中,分为 common_executor、merge_mutate_executor、moves_executor、fetch_executor 四类。这些 executor 都是 MergeTreeBackgroundExecutor 这个模板类的实例化。background_operations_assignee 得到需要执行的任务后,会将任务提交到指定的 executor 中。
因此,涉及异步执行功能的大致包含四个层次:StorageMergeTree、BackgroundJobsAssignee、BackgroundSchedulePool 以及 MergeTreeBackgroundExecutor (问题1)
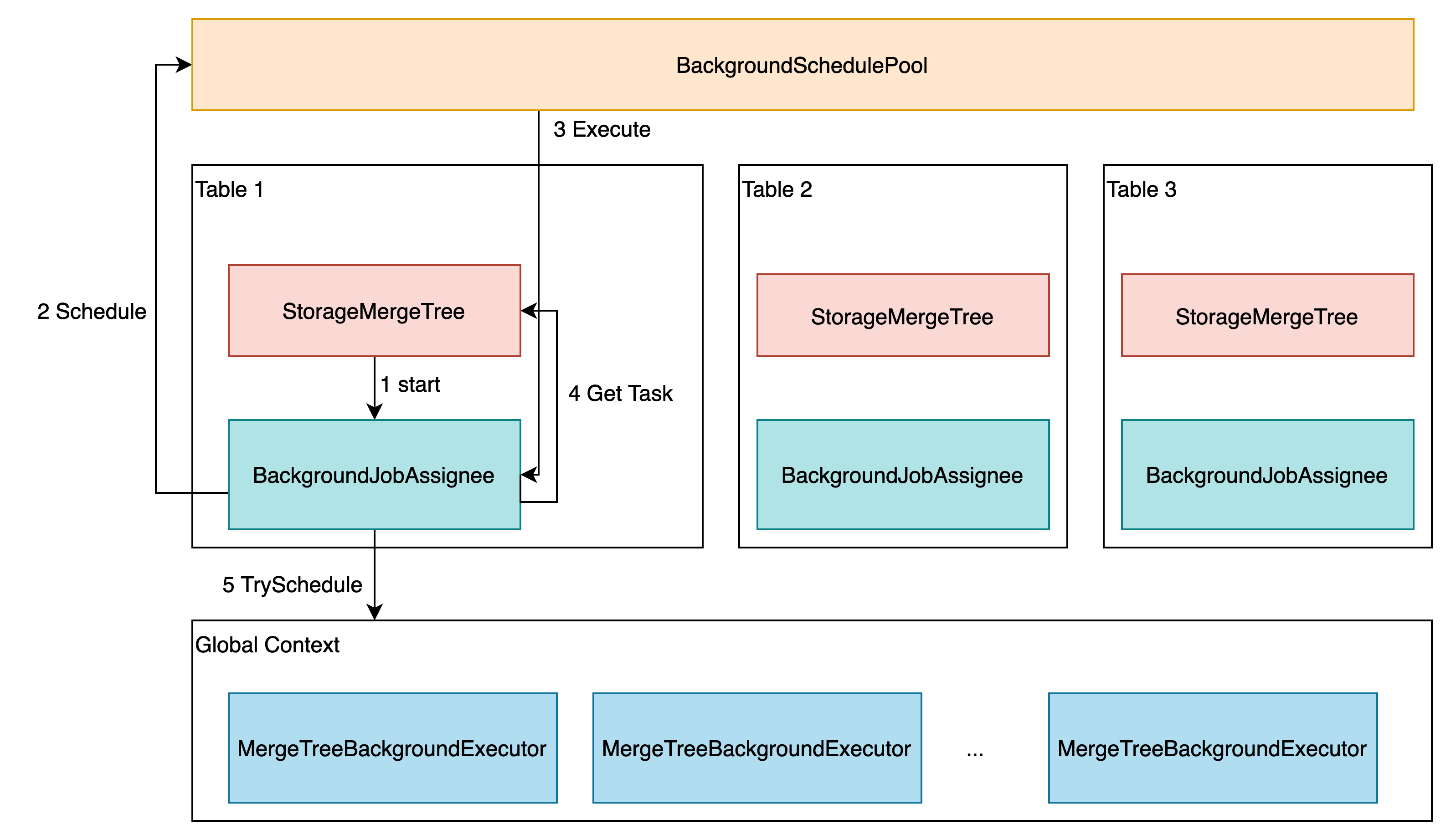
MergeTreeBackgroundExecutor 的创建是在 MergeTreeData 的构造函数中,通过调用 context 的 initializeBackgroundExecutorsIfNeeded 来执行。 所有的 MergeTree engine 都会共享这些 executors.
context_->getGlobalContext()->initializeBackgroundExecutorsIfNeeded();BackgroundSchedulePool 会在第一次 getSchedulePool 被调用时创建,每次 BackgroundJobsAssignee 执行异步调度逻辑时,都会调用到这个方法。
background_operations_assignee 的后台线程在 start 方法中启动。start 方法是在 MergeTreeData 的派生类 StorageMergeTree 的 startup() 方法中执行的,也就是在 StorageMergeTree 对应的 table 被创建或加载时,调用 background_operations_assignee 的 start 方法来启动任务的异步调度。(问题 2)
BackgroundJobsAssignee::start() 方法的启动逻辑如下:
void BackgroundJobsAssignee::start() { std::lock_guard lock(holder_mutex); if (!holder) holder = getContext()->getSchedulePool().createTask("BackgroundJobsAssignee:" + toString(type), [this]{ threadFunc(); }); holder->activateAndSchedule(); }这里 holder 会包含一个新创建的 task,并调用 activeAndSchedule() 方法来执行这个 task。 task 则主要执行一个 threadFunc 方法,定义如下:
void BackgroundJobsAssignee::threadFunc() try { bool succeed = false; switch (type) { case Type::DataProcessing: succeed = data.scheduleDataProcessingJob(*this); break; case Type::Moving: succeed = data.scheduleDataMovingJob(*this); break; } if (!succeed) postpone(); } catch (...) /// Catch any exception to avoid thread termination. { tryLogCurrentException(__PRETTY_FUNCTION__); postpone(); }这里可以看到是调用了对应 MergeTreeData 的 scheduleDataProcessingJob 方法。 scheduleDataProcessingJob 包含 task 的生成以及调度,如果没有 task,则会返回 false,最终调用 postpone() 方法。如果有 task 生成,则会调用到对应 task 相关的 MergeTreeBackgroundExecutor 的 trySchedule 方法,之后根据这个方法返回的结果,判断调用 trigger 还是 postpone。比如:
void BackgroundJobsAssignee::scheduleMergeMutateTask(ExecutableTaskPtr merge_task) { bool res = getContext()->getMergeMutateExecutor()->trySchedule(merge_task); res ? trigger() : postpone(); }由此我们看到,BackgroundJobsAssignee::threadFunc 结束时一定会调用 trigger 或者 postpone 方法。
trigger 方法直接调用 holder→schedule, 交由 BackgroundSchedulePool 去调度运行,最终会执行到 holder 包含的方法,也就是 BackgroundJobsAssignee::threadFunc 方法。由此进入到了另一次的 scheduleDataProcessingJob 的调用。res 为 false 时一般表示 task 的执行结束,这时调用 postpone 方法,进行下一次的任务调度。具体来熟,postpone 会调用 holder→scheduleAfter 方法,进行延迟调用,最终也会执行到 BackgroundJobsAssignee::threadFunc,由此达到周期性的异步任务执行的目标。(问题3)
我们接下来看 scheduleDataProcessingJob 的详细的执行流程。
scheduleDataProcessingJob
scheduleDataProcessingJob 负责处理所有数据处理相关的 job 的调度。基本的执行流程为,基于现在系统的状态,创建需要执行的后台任务,再调用 BackgroundJobsAssignee 不同的调度方法,对任务进行调度。
后台任务目前分为 MergePlainMergeTreeTask、MutatePlainMergeTreeTask 以及通用的 ExecutableLambdaAdapter 三种类型。MergePlainMergeTreeTask 与 MutatePlainMergeTreeTask 会共享 MergeMutateBackgroundExecutor,ExecutableLambdaAdapter 会提交到 OrdinaryBackgroundExecutor 去调度执行。
每次 scheduleDataProcessingJob 方法被调用时,会首先调用 selectPartsToMerge 检查是否有 data parts 需要被 merge,如果有,则创建 merge entry。如果 merge entry 不为空,则会创建一个 MergePlainMergeTreeTask,调用 BackgroundJobsAssignee::scheduleMergeMutateTask 方法将其加入后台调度队列等待执行。
如果没有 merge entry,则调用 selectPartsToMutate 检查是否有 parts 需要被修改,并创建 mutate_entry。如果 mutate_entry 不为空,则会创建 MutatePlainMergeTreeTask, 也会调用 BackgroundJobsAssignee::scheduleMergeMutateTask 来进行处理。
如果以上两个检查都没有,则会进入两个周期性的 job 逻辑,一个是 clear temporary dirs,另一个是 clear old parts。scheduleDataProcessingJob 会首先检查本次执行与上次的执行之间是否已经达到 clear temporary dirs 的时间间隔(merge_tree_clear_old_temporary_directories_interval_seconds 默认是 60s)。对于 clear old parts,也同样是先检查时间间隔是否已经达到 merge_tree_clear_old_parts_interval_seconds(默认 1s)。如果达到指定的时间间隔,就会调用 BackgroundJobsAssignee::scheduleCommonTask 来生成 executable task,加入到对应的 executor pool 中等待执行。
总结来说,scheduleDataProcessingJob 是由 BackgroundJobsAssignee::threadFunc() 来触发进行任务生成和调度。任务生成主要体现在根据 merge tree data parts 状态生成不同类型任务并提交的方面。调度则体现在周期性 old 数据的回收方面。
-
ClickHouse Merge 执行流程分析(merge parts 选择与实际执行)
基于 ClickHouse 21.11.5 版本
Parts 选择:selectPartsToMerge
scheduleDataProcessingJob 每次调用时都会首先调用 selectPartsToMerge 确定是否有需要被 merge 的 parts,如果有,会生成一个 MergeMutateSelectedEntry 类型的 merge_entry。
首先计算 max_source_parts_size, 一般为 max_bytes_to_merge_at_max_space_in_pool,默认为 150ULL * 1024 * 1024 * 1024, 也就是 150 GB,如果这个值计算出来不为 0,则开始选取 partsToMerge。如果这个值设置为 0, 应该就等同于关闭 merge 功能了。
实际的 selectPartsToMerge 功能的实现主要在 MergeTreeDataMergerMutator::selectPartsToMerge 这个方法中。首先比较粗略地找到所有可以 merge 的 part ranges。
Parts Ranges 生成
首先找到第一个可以 merge 的 data part,判断条件为没有正在参加某个 merge 或 mutate task 就可以。找到以后,标记为 prev_part, 添加到 parts_ranges 数组的最末一个 vector 中,之后继续寻找可以一起 merge 的 data parts。后续寻找的逻辑除了没有参加正在进行的 merge 或 mutate 以外,还需要判断与 prev_part 的人 mutation version 是否一致,以及是否包含了相同的 projections。全部条件满足,则将其加入到 prev_part 所在的 parts_range 中。如果不满足,则上一个 parts_range 计算结束,创建下一个 parts_range 继续进行以上的操作。
Parts Range Select
拿到所有可以 merge 的 Parts Range 以后,需要选择出一个 Parts Range 来进行本轮的 Merge。
如果定义了 TTL,会首先使用 delete_ttl_selector 进行过滤。默认情况,不会走这个逻辑。
如果 TTL 没有进行选择,则使用 SimpleMergeSelector 进行选择。
对于每个 Part Range,SimpleMergeSelector 还会遍历其每个大于 1 个 part 的子区间,基于每个子区间的 range size, sum size, max size, part number 等信息计算出一个数值,并与一个 lower_base 进行比较,如果大于 lower_base,则这个子区间可以被 merge。
每当遇到一个可以 merge 的 sub part range 时,SimpleMergeSelector 会通过一个 Estimator 计算一个分数出来,并合当前最高分进行比较,如果更少,则选取这个区间作为 best range。等所有 sub part range 都被遍历过以后,最终的 best range 会作为 selected parts range 返回。
Merge Select 算法
对每个 range 来说:
- size_normalized:0 到 1 之间。range part sum size 越大,越趋近于 1
- age_normalized :0 到 1 之间。range part 的 min_age 越大,越趋近于 1。min_age 有一个范围,最小为 10。最大值和 sum_size 相关,sum_size 越小, 最大值越接近于 24 小时。sum_size 越大,最大值越接近于 30 天。
- num_parts_normalized:0 到 1 之间。默认控制 part size 在 10 到 150 之间,将这之间的 part number 归一化处理。
- combined_ratio: 1.0 与 age_normalized + num_parts_normalized 中取更小值,也是一个 0 到 1 的值
- lowered_base: base 的默认值为 5, 取 2 到 5 中间的一个值,combined_ratio 越小,值越大。
- age 越大,num_parts 越大,lowered_base 越小
允许 merge 的条件:
- range_size * (avg_size + cost_to_add) / (max_size + cost_to_add) ≥ lowered_base
- 简单来说:part size 的差距越小,age 越大,num_parts 越大,越容易被 merge
是否最终一定会 merge 成一个 part?
- 按照默认值来说,lowered_based 最小会取到 2.0, 如果仅剩下 2 个 data parts,同时其大小相差过大的话,最终应该就不会被 merge。不太确定这种情况是否存在。
Merge 执行:MergePlainMergeTreeTask
当有 parts 被选择 merge 时,会创建一个 MergePlainMergeTreeTask 提交给 background assignee 去调度执行。MergePlainMergeTreeTask 在执行时,会不断调用 executeStep 执行不同阶段的任务。
MergePlainMergeTreeTask 创建时 state 会设置为 State::NEED_PREPARE。 在第一次 executeStep 时,会调用到 prepare() 方法,调用 MergeTreeDataMergerMutator::mergePartsToTemporaryPart 来创建一个 MergeTask 并执行。调用完成后,设置 state 为 State::NEED_EXECUTE,executeStep 返回 true,意味着这个 task 需要被 execute again。
下一次执行的时候,就会调用 prepare 阶段创建的 MergeTask 的 execute 方法,执行真正的 merge。执行完成后,会将 state 设置为 state::NEED_FINISH, 再次返回 true。下一次被调用时,调用 finish 方法, 最终调用 MergeTreeDataMergerMutator::renameMergedTemporaryPart 进行最后的 data part 处理,并将 state 设置为 state::SUCCESS, 返回 false,executeStep 不会继续循环执行,task 成功结束。