ClickHouse Merge 执行流程分析(概述与后台任务调度逻辑)
基本流程
Clickhouse 的 merge 的大致的流程为:后台线程周期性运行一个调度程序,判断是否有需要被 merge 的 data parts。如果有,则生成一个 merge task 交给后台的一个调度池等待执行。 当等待 tasks 数量小于一定值时,merge task 会被触发执行。执行时,会创建一个临时 data part 写入被 merge 的数据,执行完成后,临时 data part 按照最终 part 的 info 信息重命名,得到最终的 data part,至此一次 merge 执行结束。
以上可以看到 merge 操作主要分为几个部分:
- 后台异步周期性任务调度
- 待 merge 的 data parts 的筛选
- 实际 merge task 的执行
现在按照这三个部分来进行详细分析,本文先分析异步任务调度的逻辑.
异步任务调度
这里需要解答以下几个问题:
- 异步任务调度有几个层次?
- 每个层次的相关模块是在何时启动的?
- 如何实现周期性的调度?
这里基于 21.11.5 版本的代码来进行分析。这个版本中包含一个 BackgroundJobsAssignee 类,主要负责异步任务的生成与提交,连接 storageMergeTree 层与实际的异步任务执行层。该类定义如下:
class BackgroundJobsAssignee : public WithContext
{
private:
MergeTreeData & data;
/// Settings for execution control of background scheduling task
BackgroundTaskSchedulingSettings sleep_settings;
/// Useful for random backoff timeouts generation
pcg64 rng;
/// How many times execution of background job failed or we have
/// no new jobs.
std::atomic<size_t> no_work_done_count{0};
/// Scheduling task which assign jobs in background pool
BackgroundSchedulePool::TaskHolder holder;
/// Mutex for thread safety
std::mutex holder_mutex;
}
data 是与其对应的 MergeTreeData 对象的引用,用来访问 MergeTreeData 相关的任务生成函数。这个 MergeTreeData 是 StorageMergeTree 的基类。在 MergeTreeData 对象也会包含这个 BackgroundJobsAssignee 对象,定义如下:
class MergeTreeData : public IStorage, public WithMutableContext
{
...
protected:
...
BackgroundJobsAssignee background_operations_assignee;
BackgroundJobsAssignee background_moves_assignee;
...
}
background_operations_assignee 是主要的异步任务调度代理,background_moves_assignee 则主要负责 part move 相关的任务的执行。
每个 BackgroundJobsAssignee 在启动后,不是立即执行其后台的调度逻辑的。每次调度都需要提交到一个全局的 BackgroundSchedulePool 中进行调度,如果当前同时要运行后台调度任务的 StorageMergeTree 数量小于一个阈值,才会执行其调度逻辑,否则,会延后执行。这部分的逻辑包含在了 BackgroundSchedulePool::TaskHolder 这个类中,每个 BackgroundJobsAssignee 会包含一个 holder 的对象。
异步任务的实际执行的 executor 包含在 Context 中,分为 common_executor、merge_mutate_executor、moves_executor、fetch_executor 四类。这些 executor 都是 MergeTreeBackgroundExecutor 这个模板类的实例化。background_operations_assignee 得到需要执行的任务后,会将任务提交到指定的 executor 中。
因此,涉及异步执行功能的大致包含四个层次:StorageMergeTree、BackgroundJobsAssignee、BackgroundSchedulePool 以及 MergeTreeBackgroundExecutor (问题1)
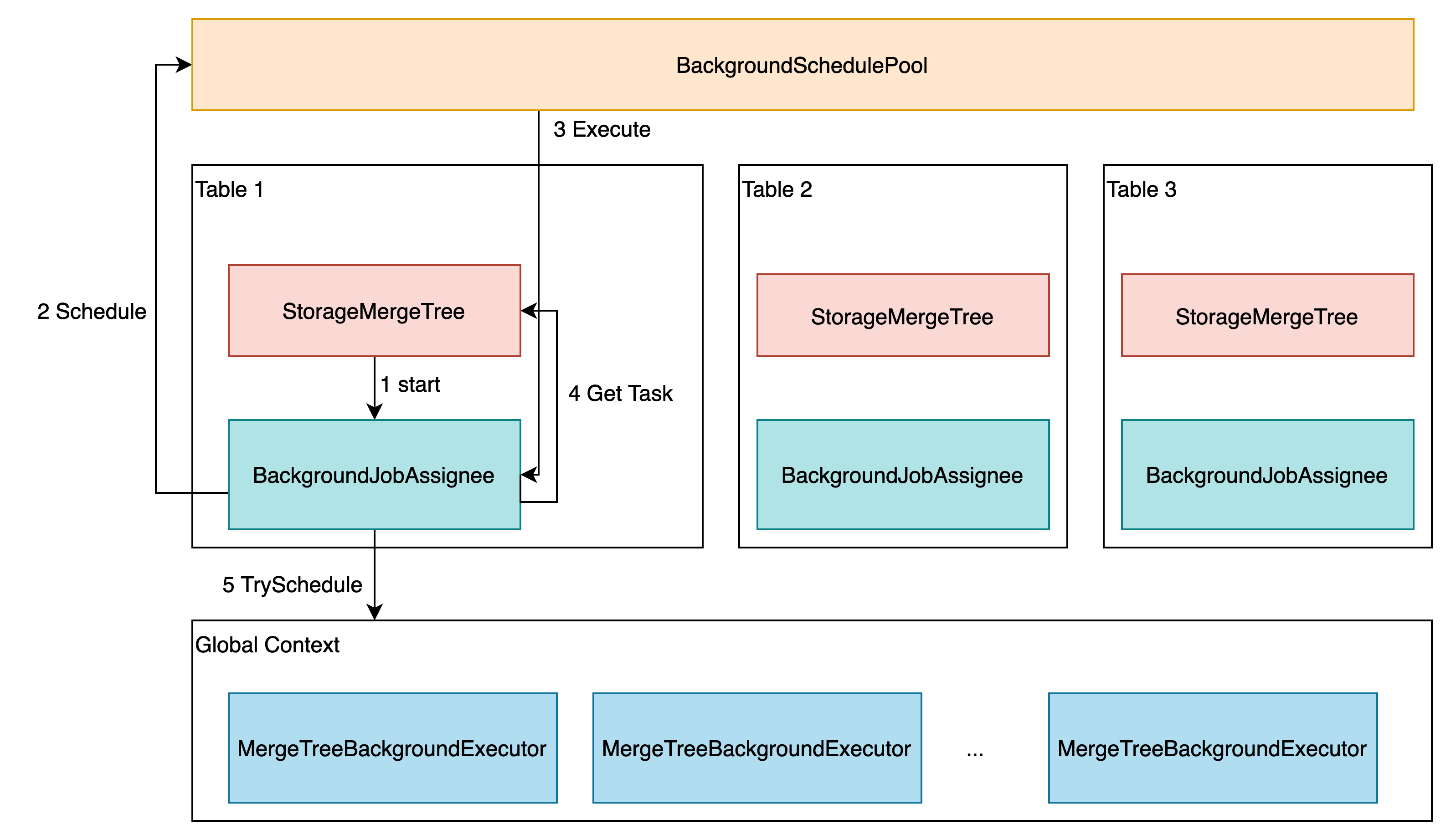
MergeTreeBackgroundExecutor 的创建是在 MergeTreeData 的构造函数中,通过调用 context 的 initializeBackgroundExecutorsIfNeeded 来执行。 所有的 MergeTree engine 都会共享这些 executors.
context_->getGlobalContext()->initializeBackgroundExecutorsIfNeeded();
BackgroundSchedulePool 会在第一次 getSchedulePool 被调用时创建,每次 BackgroundJobsAssignee 执行异步调度逻辑时,都会调用到这个方法。
background_operations_assignee 的后台线程在 start 方法中启动。start 方法是在 MergeTreeData 的派生类 StorageMergeTree 的 startup() 方法中执行的,也就是在 StorageMergeTree 对应的 table 被创建或加载时,调用 background_operations_assignee 的 start 方法来启动任务的异步调度。(问题 2)
BackgroundJobsAssignee::start() 方法的启动逻辑如下:
void BackgroundJobsAssignee::start()
{
std::lock_guard lock(holder_mutex);
if (!holder)
holder = getContext()->getSchedulePool().createTask("BackgroundJobsAssignee:" + toString(type), [this]{ threadFunc(); });
holder->activateAndSchedule();
}
这里 holder 会包含一个新创建的 task,并调用 activeAndSchedule() 方法来执行这个 task。 task 则主要执行一个 threadFunc 方法,定义如下:
void BackgroundJobsAssignee::threadFunc()
try
{
bool succeed = false;
switch (type)
{
case Type::DataProcessing:
succeed = data.scheduleDataProcessingJob(*this);
break;
case Type::Moving:
succeed = data.scheduleDataMovingJob(*this);
break;
}
if (!succeed)
postpone();
}
catch (...) /// Catch any exception to avoid thread termination.
{
tryLogCurrentException(__PRETTY_FUNCTION__);
postpone();
}
这里可以看到是调用了对应 MergeTreeData 的 scheduleDataProcessingJob 方法。 scheduleDataProcessingJob 包含 task 的生成以及调度,如果没有 task,则会返回 false,最终调用 postpone() 方法。如果有 task 生成,则会调用到对应 task 相关的 MergeTreeBackgroundExecutor 的 trySchedule 方法,之后根据这个方法返回的结果,判断调用 trigger 还是 postpone。比如:
void BackgroundJobsAssignee::scheduleMergeMutateTask(ExecutableTaskPtr merge_task)
{
bool res = getContext()->getMergeMutateExecutor()->trySchedule(merge_task);
res ? trigger() : postpone();
}
由此我们看到,BackgroundJobsAssignee::threadFunc 结束时一定会调用 trigger 或者 postpone 方法。
trigger 方法直接调用 holder→schedule, 交由 BackgroundSchedulePool 去调度运行,最终会执行到 holder 包含的方法,也就是 BackgroundJobsAssignee::threadFunc 方法。由此进入到了另一次的 scheduleDataProcessingJob 的调用。res 为 false 时一般表示 task 的执行结束,这时调用 postpone 方法,进行下一次的任务调度。具体来熟,postpone 会调用 holder→scheduleAfter 方法,进行延迟调用,最终也会执行到 BackgroundJobsAssignee::threadFunc,由此达到周期性的异步任务执行的目标。(问题3)
我们接下来看 scheduleDataProcessingJob 的详细的执行流程。
scheduleDataProcessingJob
scheduleDataProcessingJob 负责处理所有数据处理相关的 job 的调度。基本的执行流程为,基于现在系统的状态,创建需要执行的后台任务,再调用 BackgroundJobsAssignee 不同的调度方法,对任务进行调度。
后台任务目前分为 MergePlainMergeTreeTask、MutatePlainMergeTreeTask 以及通用的 ExecutableLambdaAdapter 三种类型。MergePlainMergeTreeTask 与 MutatePlainMergeTreeTask 会共享 MergeMutateBackgroundExecutor,ExecutableLambdaAdapter 会提交到 OrdinaryBackgroundExecutor 去调度执行。
每次 scheduleDataProcessingJob 方法被调用时,会首先调用 selectPartsToMerge 检查是否有 data parts 需要被 merge,如果有,则创建 merge entry。如果 merge entry 不为空,则会创建一个 MergePlainMergeTreeTask,调用 BackgroundJobsAssignee::scheduleMergeMutateTask 方法将其加入后台调度队列等待执行。
如果没有 merge entry,则调用 selectPartsToMutate 检查是否有 parts 需要被修改,并创建 mutate_entry。如果 mutate_entry 不为空,则会创建 MutatePlainMergeTreeTask, 也会调用 BackgroundJobsAssignee::scheduleMergeMutateTask 来进行处理。
如果以上两个检查都没有,则会进入两个周期性的 job 逻辑,一个是 clear temporary dirs,另一个是 clear old parts。scheduleDataProcessingJob 会首先检查本次执行与上次的执行之间是否已经达到 clear temporary dirs 的时间间隔(merge_tree_clear_old_temporary_directories_interval_seconds 默认是 60s)。对于 clear old parts,也同样是先检查时间间隔是否已经达到 merge_tree_clear_old_parts_interval_seconds(默认 1s)。如果达到指定的时间间隔,就会调用 BackgroundJobsAssignee::scheduleCommonTask 来生成 executable task,加入到对应的 executor pool 中等待执行。
总结来说,scheduleDataProcessingJob 是由 BackgroundJobsAssignee::threadFunc() 来触发进行任务生成和调度。任务生成主要体现在根据 merge tree data parts 状态生成不同类型任务并提交的方面。调度则体现在周期性 old 数据的回收方面。